


Redis (Remote Directory Server) is an in-memory data structure store. It is a disk-persistent key-value database with support for multiple data structures or data types.
Redis is an open source (BSD licensed), in-memory data structure store, used as a database, cache, and message broker.
Redis provides data structures such as strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperloglogs, geospatial indexes, and streams.
Redis has built-in replication, Lua scripting, LRU eviction, transactions, and different levels of on-disk persistence, and provides high availability via Redis Sentinel and automatic partitioning with Redis Cluster.
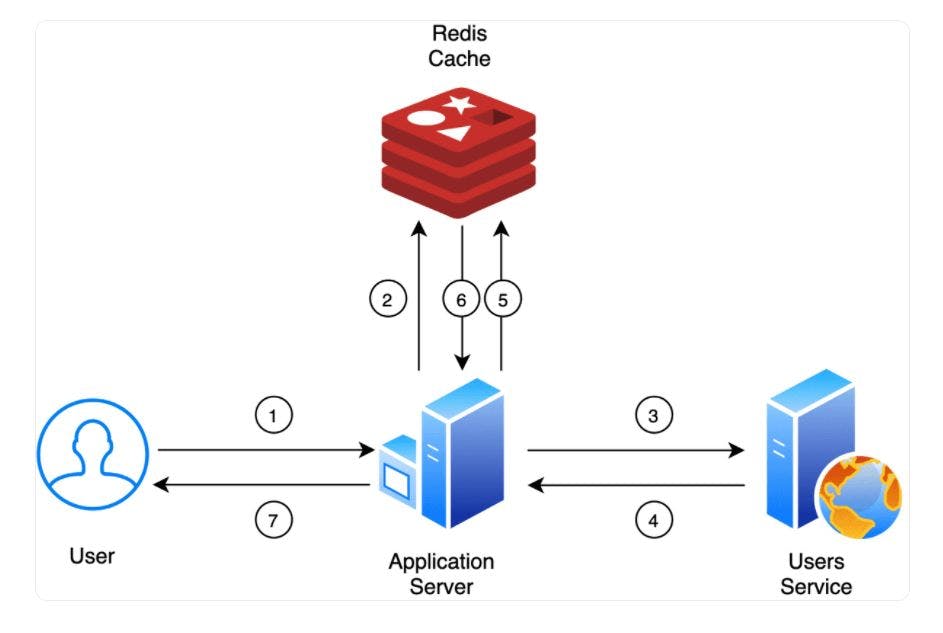
How does it work ?
Redis is a No SQL database which works on the concept of key-value pair. All Redis data resides in-memory, in contrast to databases that store data on disk or SSDs. By eliminating the need to access disks, in-memory data stores such as Redis avoid seek time delays and can access data in microseconds.
Redis features versatile data structures, high availability, geospatial, Lua scripting, transactions, on-disk persistence, and cluster support making it simpler to build real-time internet scale apps.
Advantages of Redis
Exceptionally fast
Redis is very fast and can perform about 110000 SETs per second, about 81000 GETs per second.
Supports rich data types
Redis natively supports most of the datatypes that developers already know such as list, set, sorted set, and hashes. This makes it easy to solve a variety of problems as we know which problem can be handled better by which data type.
Atomic Operations
All Redis operations are atomic, which ensures that if two clients concurrently access, Redis server will receive the updated value.
Multi-utility tool
Redis is a multi-utility tool and can be used in a number of use cases such as caching, messaging-queues (Redis natively supports Publish/Subscribe), any short-lived data in your application, such as web application sessions, web page hit counts, etc.
Master/Slave Replication
Redis follows a very simple and fast Master/Slave replication. It takes only one line in the configuration file to set it up, and 21 seconds for a Slave to complete the initial sync of 10 MM key set on an Amazon EC2 instance.
Transactions in Redis
Redis transactions allow the execution of a group of commands in a single step.
Following are the two properties of Transactions.
All commands in a transaction are sequentially executed as a single isolated operation. It is not possible that a request issued by another client is served in the middle of the execution of a Redis transaction.
Redis transaction is also atomic. Atomic means either all of the commands or none are processed.
Client Connection in Redis
Redis accepts clients’ connections on the configured listening TCP port and on the Unix socket, if enabled.
When a new client connection is accepted, the following operations are performed −
The client socket is put in non-blocking state since Redis uses multiplexing and non-blocking I/O.
The TCP_NODELAY option is set in order to ensure that we don't have delays in our connection.
A readable file event is created so that Redis is able to collect the client queries as soon as new data is available to be read on the socket.
Pipelining in Redis
The basic meaning of pipelining is, the client can send multiple requests to the server without waiting for the replies at all, and finally reads the replies in a single step.
Redis is a TCP server and supports request/response protocol. In Redis, a request is accomplished with the following steps −
The client sends a query to the server, and reads from the socket, usually in a blocking way, for the server response.
The server processes the command and sends the response back to the client.
Benefits of Pipelining
The benefit of this technique is a drastically improved protocol performance.
The speedup gained by pipelining ranges from a factor of five for connections to localhost up to a factor of at least one hundred over slower internet connections.
Redis Vs Memcached
Memcached is in-memory key-value store, originally intended for caching purpose while Redis is in-memory data structure store, used as database, cache and message broker.
Memcached follows Key-value store database model and Redis also follows Key-value store database model.
MemcacheD is more memory efficient than Redis because it consumes comparatively less memory resources for metadata. Redis is more memory efficient, only after you use Redis hashes.
Memcached doesn't use persistent data. While using Memcached, data might be lost with a restart and rebuilding cache is a costly process. Redis can handle persistent data. By default it syncs data to the disk at least every 2 seconds, offering optional & tuneable data persistence meant to bootstrap the cache after a planned shutdown or an unintentional failure. While we tend to regard the data in caches as volatile and transient, persisting data to disk can be quite valuable in caching scenarios.
Memcached does not support replication. Redis supports master-slave replication.
MemcacheD stores variables in its memory and retrieves any information directly from the server memory instead of hitting the database again. Redis is like a database that resides in memory. It executes (reads and writes) a key/value pair from its database to return the result set. That's why it is used by develepors for real-time metrics and analytics.
MemcacheD uses only strings and integers in its data structure. So, everything you save can either be a string or an integer. It is complicated because with integers, the only data manipulation you can do is adding or subtracting them. If you need to save arrays or objects, you will have to serialize them first and then save them. To read them back, you will need to un-serialize. Redis has stronger data structures, which can handle not only strings integers but also binary-safe strings, lists of binary-safe strings, sets of binary-safe strings and sorted sets.