Intro to Machine Learning

Machine learning is about extracting the knowledge from data. It is a research field at the intersection of statistics, artificial intelligence, and computer science and is also known as predictive analytics or statistical learning.
The application of machine learning methods has in recent years become ubiquitous in everyday life. From automatic recommendations of which movies to watch, to what food to order or which products to buy, to personalized online radio and recognizing your friends in your photos, many modern websites and devices have machine learning algorithms at their core.
Machine Learning
In theory, machine learning is a subset of computer science that uses data and algorithms to mimic the way humans learn. You see, computers are not like humans. They can only do what we explicitly program them to do.
What makes machine learning unique is that it programs machines to learn as we do. Through machine learning, computers and software can improve using new information.
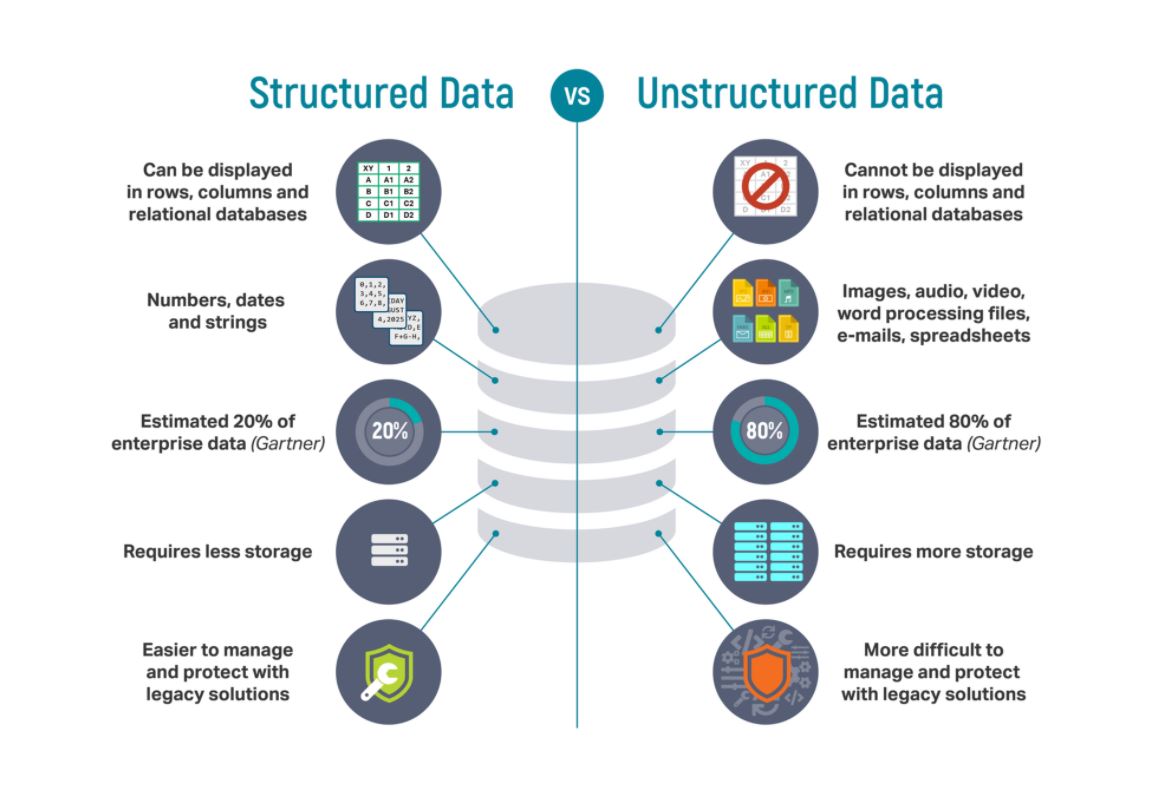
Structured Data
Structured data — typically categorized as quantitative data — is highly organized and easily decipherable by machine learning algorithms. Developed by IBM in 1974, structured query language (SQL) is the programming language used to manage structured data. By using a relational (SQL) database, business users can quickly input, search and manipulate structured data.
Unstructured Data
Unstructured data is categorized as qualitative data, cannot be processed and analyzed via conventional data tools and methods. Since unstructured data does not have a predefined data model, it is best managed in non-relational (NoSQL) databases. Another way to manage unstructured data is to use data lakes to preserve it in raw form.
The importance of unstructured data is rapidly increasing. Recent projections indicate that unstructured data is over 80% of all enterprise data, while 95% of businesses prioritize unstructured data management.
Semi structured data
Semi-structured data (e.g., JSON, CSV, XML) is the “bridge” between structured and unstructured data. It does not have a predefined data model and is more complex than structured data, yet easier to store than unstructured data.
Semi-structured data uses “metadata” (e.g., tags and semantic markers) to identify specific data characteristics and scale data into records and preset fields. Metadata ultimately enables semi-structured data to be better cataloged, searched and analyzed than unstructured data.
Example of metadata usage: An online article displays a headline, a snippet, a featured image, image alt-text, slug, etc., which helps differentiate one piece of web content from similar pieces. Example of semi-structured data vs. structured data: A tab-delimited file containing customer data versus a database containing CRM tables. Example of semi-structured data vs. unstructured data: A tab-delimited file versus a list of comments from a customer’s Instagram.
Types of Machine Learning
There are three main types of machine learning: supervised, unsupervised, and reinforcement learning.
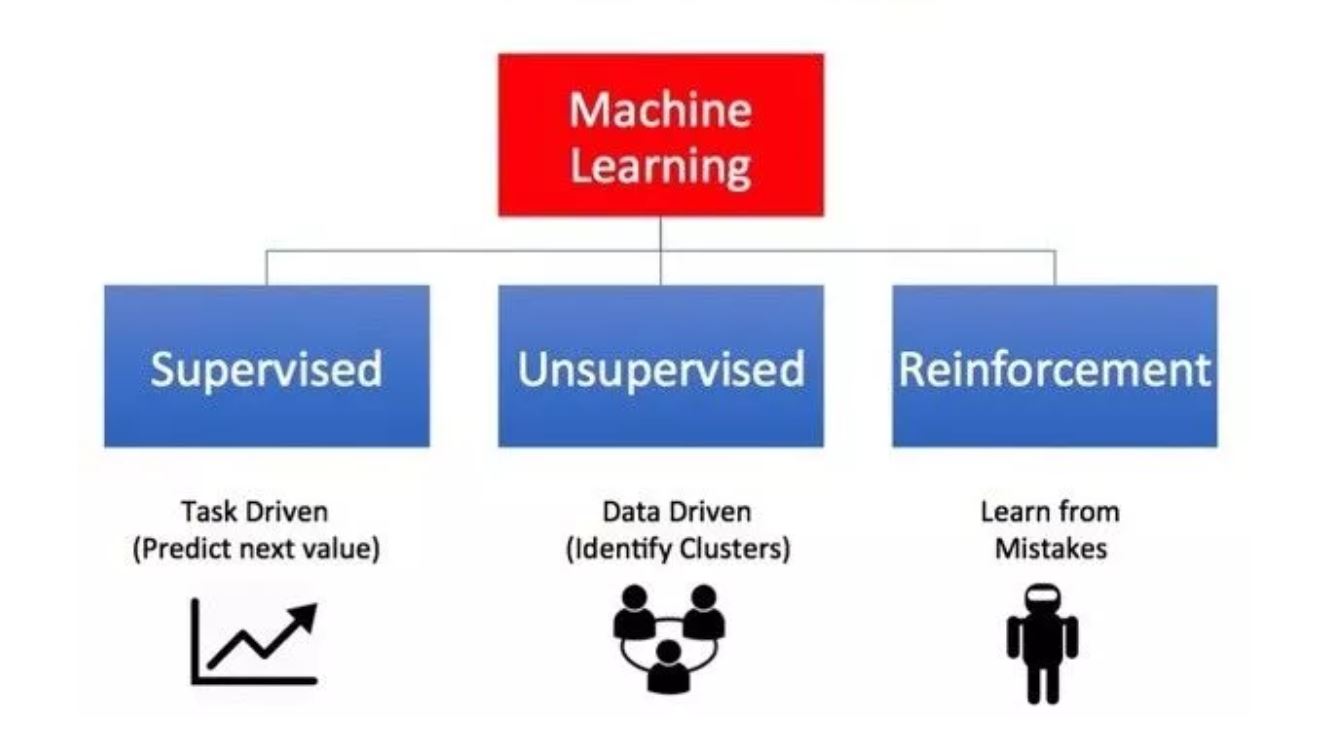
Supervised Learning
Supervised learning is the most popular paradigm for machine learning. It is often described as task-oriented because of this. It is highly focused on a singular task, feeding more and more examples to the algorithm until it can accurately perform on that task. This is the learning type that you will most likely encounter, as it is exhibited in many of the following common applications:
- Advertisement Popularity
- Spam Classification
- Face Recognition
Unsupervised learning
Unsupervised learning is very much the opposite of supervised learning. It features no labels. Instead, our algorithm would be fed a lot of data and given the tools to understand the properties of the data. From there, it can learn to group, cluster, and/or organize the data in a way such that a human (or other intelligent algorithm) can come in and make sense of the newly organized data.
Reinforcement Learning
Reinforcement learning is fairly different when compared to supervised and unsupervised learning.
It is defined as a Machine Learning method that is concerned with how software agents should take actions in an environment. Reinforcement Learning is a part of the deep learning method that helps you to maximize some portion of the cumulative reward.
This neural network learning method helps you to learn how to attain a complex objective or maximize a specific dimension over many steps.
Why use Python
It combines the power of general-purpose programming languages with the ease of use of domain-specific scripting languages like MATLAB or R. Python has libraries for data loading, visualization, statistics, natural language processing, image processing, and more. This vast toolbox provides data scientists with a large array of general- and special-purpose functionality. One of the main advantages of using Python is the ability to interact directly with the code, using a terminal or other tools like the Jupyter Notebook, which we’ll look at shortly. Machine learning and data analysis are fundamentally iterative processes, in which the data drives the analysis. It is essential for these processes to have tools that allow quick iteration and easy interaction.
As a general-purpose programming language, Python also allows for the creation of complex graphical user interfaces (GUIs) and web services, and for integration into existing systems.




