Git Clone vs Git Fork

The key difference between Git clone and fork comes down to how much control and independence you want over the codebase once you've copied it.
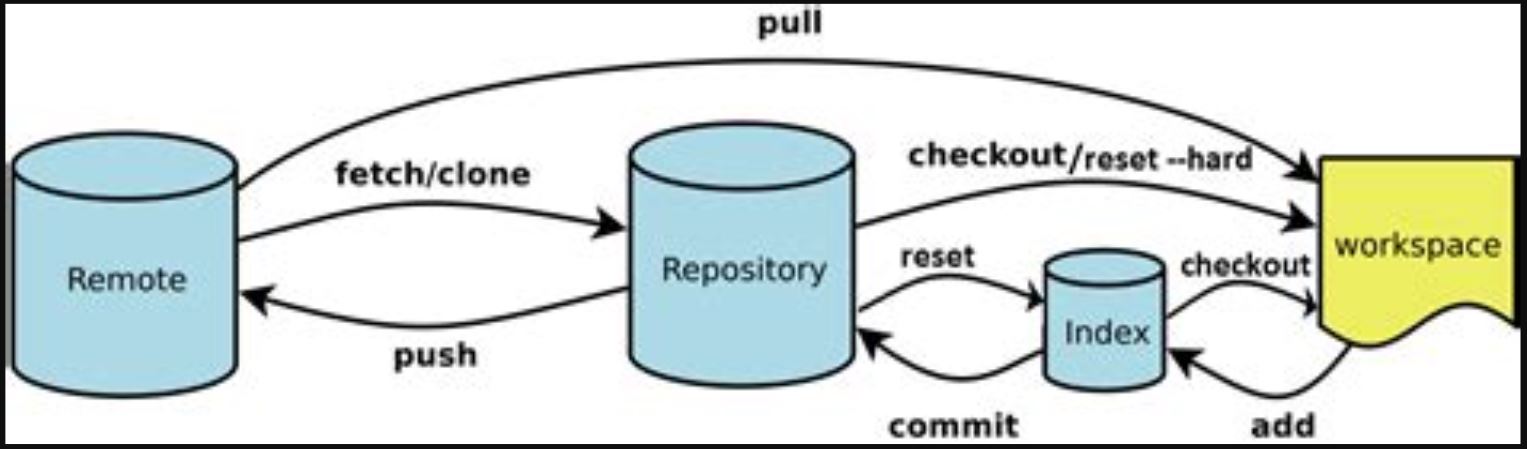
If you clone a repository, it means that you're making a copy of it and storing it on your personal computer's hard drive, and therefore if you work on a piece of the repository and want to submit a change (aka make a pull request), you have to upload the edited file back onto the GitHub server.
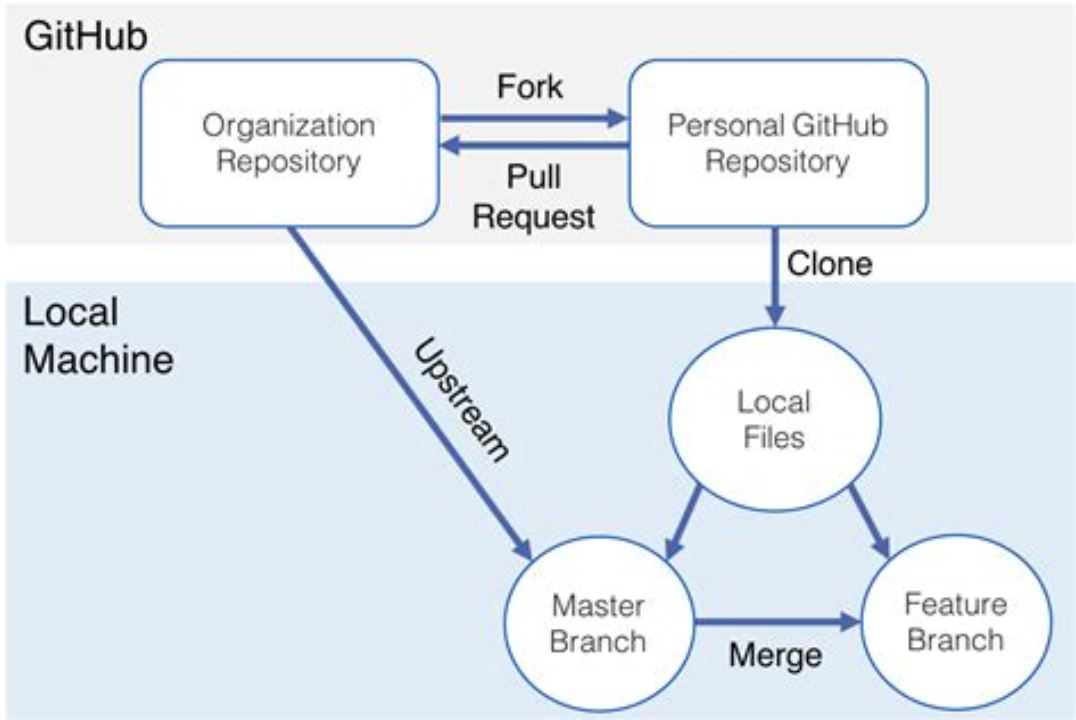
If you fork a repository, though, it means that you make a copy that lives in your user account on the GitHub server (so no time or data is lost between downloading and uploading the repository between your computer and GitHub). It lives on the GitHub server, which makes it easier to pull back into the original repository/webpage code after you make edits to the code.
Changes made to the forked repository can be merged with the original repository via a pull request. Pull request knocks the repository owner and tell that some changes are made, please merge these changes to your repository.
On the other hand, changes made on the local machine (cloned repository) can be pushed to the upstream repository directly.
For this, the user must have the write access for the repository otherwise this is not possible. If the user does not have the write access, the only way to go is through the forked request.
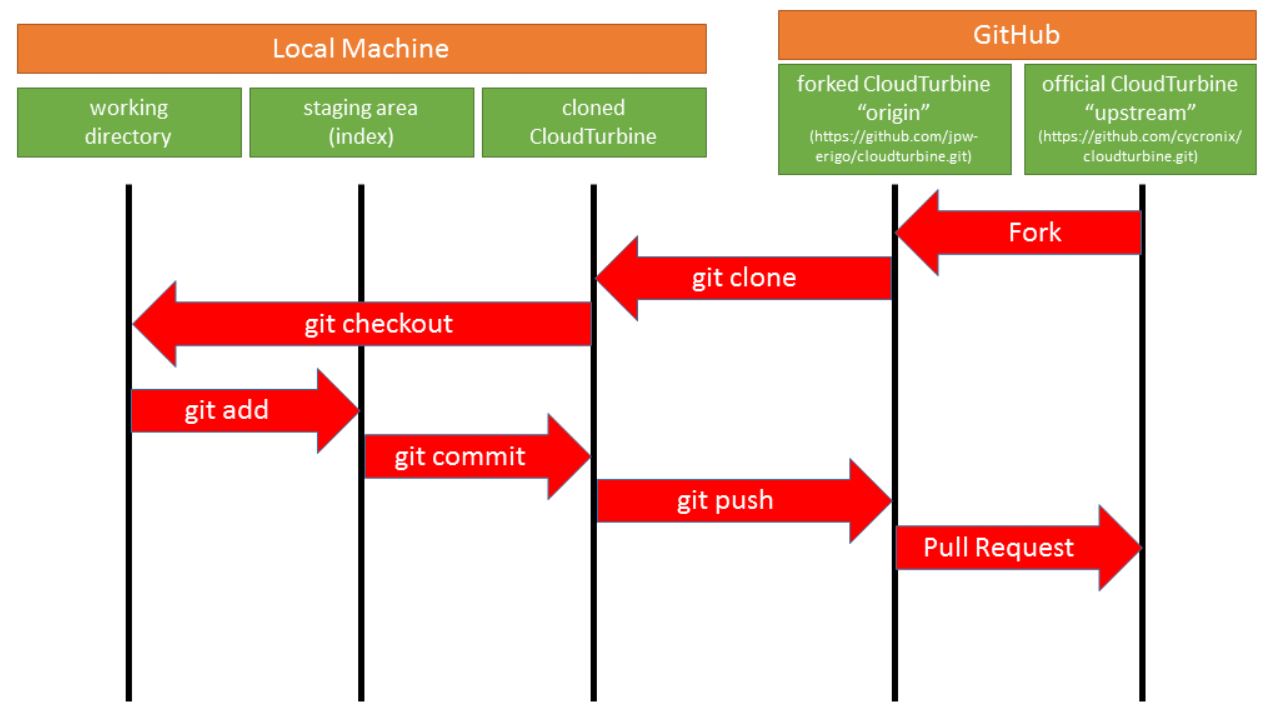
So in that case, the changes made in the cloned repository are first pushed to the forked repository and then a pull request is created.
It is a better option to fork before clone if the user is not declared as a contributor and it is a third party repository (not of the organization).
You might not have write permissions to work directly on the main repository. (Mostly this model is used for open source projects). If everyone clone and directly work on that main project repository/branch, then it’ll be very hard to manage.




